Automatic differentiation with JAX¶
Here we look into automatic differentiation, which can speed up fits with very many parameters.
iminuit’s minimization algorithm MIGRAD uses a mix of gradient descent and Newton’s method to find the minimum. Both require a first derivative, which MIGRAD usually computes numerically from finite differences. This requires many function evaluations and the gradient may not be accurate. As an alternative, iminuit also allows the user to compute the gradient and pass it to MIGRAD.
Although computing derivatives is often straight-forward, it is usually too much hassle to do manually. Automatic differentiation (AD) is an interesting alternative, it allows one to compute exact derivatives efficiently for pure Python/numpy functions. We demonstrate automatic differentiation with the JAX module, which can not only compute derivatives, but also accelerates the computation of Python code (including the gradient code) with a just-in-time compiler.
Recommended read: Gentle introduction to AD
Fit of a gaussian model to a histogram¶
We fit a gaussian to a histogram using a maximum-likelihood approach based on Poisson statistics. This example is used to investigate how automatic differentiation can accelerate a typical fit in a counting experiment.
To compare fits with and without passing an analytic gradient fairly, we use Minuit.strategy = 0, which prevents Minuit from automatically computing the Hesse matrix after the fit.
[21]:
# !pip install jax jaxlib matplotlib numpy iminuit numba-stats
import jax
from jax import numpy as jnp # replacement for normal numpy
from jax.scipy.special import erf # replacement for scipy.special.erf
from iminuit import Minuit
import numba as nb
import numpy as np # original numpy still needed, since jax does not cover full API
jax.config.update("jax_enable_x64", True) # enable float64 precision, default is float32
print(f"JAX version {jax.__version__}")
print(f"numba version {nb.__version__}")
JAX version 0.4.8
numba version 0.57.0
We generate some toy data and write the negative log-likelihood (nll) for a fit to binned data, assuming Poisson-distributed counts.
Note: We write all statistical functions in pure Python code, to demonstrate Jax’s ability to automatically differentiate and JIT compile this code. In practice, one should import JIT-able statistical distributions from jax.scipy.stats. The library versions can be expected to have fewer bugs and to be faster and more accurate than hand-written code.
[22]:
# generate some toy data
rng = np.random.default_rng(seed=1)
n, xe = np.histogram(rng.normal(size=10000), bins=1000)
def cdf(x, mu, sigma):
# cdf of a normal distribution, needed to compute the expected counts per bin
# better alternative for real code: from jax.scipy.stats.norm import cdf
z = (x - mu) / sigma
return 0.5 * (1 + erf(z / np.sqrt(2)))
def nll(par): # negative log-likelihood with constants stripped
amp = par[0]
mu, sigma = par[1:]
p = cdf(xe, mu, sigma)
mu = amp * jnp.diff(p)
result = jnp.sum(mu - n + n * jnp.log(n / (mu + 1e-100) + 1e-100))
return result
Let’s check results from all combinations of using JIT and gradient and then compare the execution times.
[23]:
start_values = (1.5 * np.sum(n), 1.0, 2.0)
limits = ((0, None), (None, None), (0, None))
def make_and_run_minuit(fcn, grad=None):
m = Minuit(fcn, start_values, grad=grad, name=("amp", "mu", "sigma"))
m.errordef = Minuit.LIKELIHOOD
m.limits = limits
m.strategy = 0 # do not explicitly compute hessian after minimisation
m.migrad()
return m
[24]:
m1 = make_and_run_minuit(nll)
m1.fmin
[24]:
| Migrad | |
|---|---|
| FCN = 496.2 | Nfcn = 66 |
| EDM = 1.84e-08 (Goal: 0.0001) | |
| Valid Minimum | Below EDM threshold (goal x 10) |
| No parameters at limit | Below call limit |
| Hesse ok | Covariance APPROXIMATE |
[25]:
m2 = make_and_run_minuit(nll, grad=jax.grad(nll))
m2.fmin
[25]:
| Migrad | |
|---|---|
| FCN = 496.2 | Nfcn = 26, Ngrad = 6 |
| EDM = 1.84e-08 (Goal: 0.0001) | time = 0.2 sec |
| Valid Minimum | Below EDM threshold (goal x 10) |
| No parameters at limit | Below call limit |
| Hesse ok | Covariance APPROXIMATE |
[26]:
m3 = make_and_run_minuit(jax.jit(nll))
m3.fmin
[26]:
| Migrad | |
|---|---|
| FCN = 496.2 | Nfcn = 66 |
| EDM = 1.84e-08 (Goal: 0.0001) | |
| Valid Minimum | Below EDM threshold (goal x 10) |
| No parameters at limit | Below call limit |
| Hesse ok | Covariance APPROXIMATE |
[27]:
m4 = make_and_run_minuit(jax.jit(nll), grad=jax.jit(jax.grad(nll)))
m4.fmin
[27]:
| Migrad | |
|---|---|
| FCN = 496.2 | Nfcn = 26, Ngrad = 6 |
| EDM = 1.84e-08 (Goal: 0.0001) | time = 0.2 sec |
| Valid Minimum | Below EDM threshold (goal x 10) |
| No parameters at limit | Below call limit |
| Hesse ok | Covariance APPROXIMATE |
[28]:
from numba_stats import norm # numba jit-able version of norm
@nb.njit
def nb_nll(par):
amp = par[0]
mu, sigma = par[1:]
p = norm.cdf(xe, mu, sigma)
mu = amp * np.diff(p)
result = np.sum(mu - n + n * np.log(n / (mu + 1e-323) + 1e-323))
return result
m5 = make_and_run_minuit(nb_nll)
m5.fmin
[28]:
| Migrad | |
|---|---|
| FCN = 496.2 | Nfcn = 82 |
| EDM = 5.31e-05 (Goal: 0.0001) | time = 1.0 sec |
| Valid Minimum | Below EDM threshold (goal x 10) |
| No parameters at limit | Below call limit |
| Hesse ok | Covariance APPROXIMATE |
[29]:
from timeit import timeit
times = {
"no JIT, no grad": "m1",
"no JIT, grad": "m2",
"jax JIT, no grad": "m3",
"jax JIT, grad": "m4",
"numba JIT, no grad": "m5",
}
for k, v in times.items():
t = timeit(
f"{v}.values = start_values; {v}.migrad()",
f"from __main__ import {v}, start_values",
number=1,
)
times[k] = t
[30]:
from matplotlib import pyplot as plt
x = np.fromiter(times.values(), dtype=float)
xmin = np.min(x)
y = -np.arange(len(times))
plt.barh(y, x)
for yi, k, v in zip(y, times, x):
plt.text(v, yi, f"{v/xmin:.1f}x")
plt.yticks(y, times.keys())
for loc in ("top", "right"):
plt.gca().spines[loc].set_visible(False)
plt.xlabel("execution time / s");
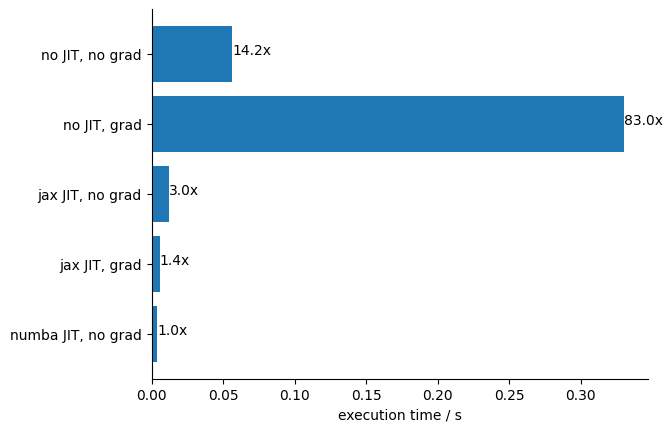
Conclusions:
As expected, the best results with JAX are obtained by JIT compiling function and gradient and using the gradient in the minimization. However, the performance of the Numba JIT compiled function is comparable even without computing the gradient.
JIT compiling the cost function with JAX but not using the gradient also gives good performance, but worse than using Numba for the same.
Combining the JAX JIT with the JAX gradient calculation is very important. Using only the Python-computed gradient even reduces performance in this example.
In general, the gain from using a gradient is larger for functions with hundreds of parameters, as is common in machine learning. Human-made models often have less than 10 parameters, and then the gain is not so dramatic.
Computing covariance matrices with JAX¶
Automatic differentiation gives us another way to compute uncertainties of fitted parameters. MINUIT compute the uncertainties with the HESSE algorithm by default, which computes the matrix of second derivates approximately using finite differences and inverts this.
Let’s compare the output of HESSE with the exact (within floating point precision) computation using automatic differentiation.
[31]:
m4.hesse()
cov_hesse = m4.covariance
def jax_covariance(par):
return jnp.linalg.inv(jax.hessian(nll)(par))
par = np.array(m4.values)
cov_jax = jax_covariance(par)
print(
f"sigma[amp] : HESSE = {cov_hesse[0, 0] ** 0.5:6.1f}, JAX = {cov_jax[0, 0] ** 0.5:6.1f}"
)
print(
f"sigma[mu] : HESSE = {cov_hesse[1, 1] ** 0.5:6.4f}, JAX = {cov_jax[1, 1] ** 0.5:6.4f}"
)
print(
f"sigma[sigma]: HESSE = {cov_hesse[2, 2] ** 0.5:6.4f}, JAX = {cov_jax[2, 2] ** 0.5:6.4f}"
)
sigma[amp] : HESSE = 100.0, JAX = 100.0
sigma[mu] : HESSE = 0.0100, JAX = 0.0100
sigma[sigma]: HESSE = 0.0071, JAX = 0.0071
Success, HESSE and JAX give the same answer within the relevant precision.
Note: If you compute the covariance matrix in this way from a least-squares cost function instead of a negative log-likelihood, you must multiply it by 2.
Let us compare the performance of HESSE with Jax.
[32]:
%%timeit -n 1 -r 3
m = Minuit(nll, par)
m.errordef = Minuit.LIKELIHOOD
m.hesse()
30.4 ms ± 1.37 ms per loop (mean ± std. dev. of 3 runs, 1 loop each)
[33]:
%%timeit -n 1 -r 3
jax_covariance(par)
89 ms ± 28.6 ms per loop (mean ± std. dev. of 3 runs, 1 loop each)
The computation with Jax is slower, but it is also more accurate (although the added precision is not relevant).
Minuit’s HESSE algorithm still makes sense today. It has the advantage that it can process any function, while Jax cannot. Jax cannot differentiate a function that calls into C/C++ code or Cython code, for example.
Final note: If we JIT compile jax_covariance, it greatly outperforms Minuit’s HESSE algorithm, but that only makes sense if you need to compute the hessian at different parameter values, so that the extra time spend to compile is balanced by the time saved over many invocations. This is not what happens here, the Hessian in only needed at the best fit point.
[34]:
%%timeit -n 1 -r 3 jit_jax_covariance = jax.jit(jax_covariance); jit_jax_covariance(par)
jit_jax_covariance(par)
187 µs ± 28.1 µs per loop (mean ± std. dev. of 3 runs, 1 loop each)
It is much faster… but only because the compilation cost is excluded here.
[35]:
%%timeit -n 1 -r 1
# if we include the JIT compilation cost, the performance drops dramatically
@jax.jit
def jax_covariance(par):
return jnp.linalg.inv(jax.hessian(nll)(par))
jax_covariance(par)
496 ms ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
With compilation cost included, it is much slower.
Conclusion: Using the JIT compiler makes a lot of sense if the covariance matrix has to be computed repeatedly for the same cost function but different parameters, but this is not the case when we use it to compute parameter errors.
Fit data points with uncertainties in x and y¶
Let’s say we have some data points \((x_i \pm \sigma_{x,i}, y_i \pm \sigma_{y,i})\) and we have a model \(y=f(x)\) that we want to adapt to this data. If \(\sigma_{x,i}\) was zero, we could use the usual least-squares method, minimizing the sum of squared residuals \(r^2_i = (y_i - f(x_i))^2 / \sigma^2_{y,i}\). Here, we don’t know where to evaluate \(f(x)\), since the exact \(x\)-location is only known up to \(\sigma_{x,i}\).
We can approximately extend the standard least-squares method to handle this case. We use that the uncertainty along the \(x\)-axis can be converted into an additional uncertainty along the \(y\)-axis with error propagation,
Using this, we obtain modified squared residuals
We demonstrate this with a fit of a polynomial.
[36]:
# polynomial model
def f(x, par):
return jnp.polyval(par, x)
# true polynomial f(x) = x^2 + 2 x + 3
par_true = np.array((1, 2, 3))
# grad computes derivative with respect to the first argument
f_prime = jax.jit(jax.grad(f))
# checking first derivative f'(x) = 2 x + 2
assert f_prime(0.0, par_true) == 2
assert f_prime(1.0, par_true) == 4
assert f_prime(2.0, par_true) == 6
# ok!
# generate toy data
n = 30
data_x = np.linspace(-4, 7, n)
data_y = f(data_x, par_true)
rng = np.random.default_rng(seed=1)
sigma_x = 0.5
sigma_y = 5
data_x += rng.normal(0, sigma_x, n)
data_y += rng.normal(0, sigma_y, n)
[37]:
plt.errorbar(data_x, data_y, sigma_y, sigma_x, fmt="o");
[38]:
# define the cost function
@jax.jit
def cost(par):
result = 0.0
for xi, yi in zip(data_x, data_y):
y_var = sigma_y ** 2 + (f_prime(xi, par) * sigma_x) ** 2
result += (yi - f(xi, par)) ** 2 / y_var
return result
cost.errordef = Minuit.LEAST_SQUARES
# test the jit-ed function
cost(np.zeros(3))
[38]:
Array(876.49545695, dtype=float64)
[39]:
m = Minuit(cost, np.zeros(3))
m.migrad()
[39]:
| Migrad | |
|---|---|
| FCN = 23.14 | Nfcn = 91 |
| EDM = 3.12e-05 (Goal: 0.0002) | |
| Valid Minimum | Below EDM threshold (goal x 10) |
| No parameters at limit | Below call limit |
| Hesse ok | Covariance accurate |
| Name | Value | Hesse Error | Minos Error- | Minos Error+ | Limit- | Limit+ | Fixed | |
|---|---|---|---|---|---|---|---|---|
| 0 | x0 | 1.25 | 0.15 | |||||
| 1 | x1 | 1.5 | 0.5 | |||||
| 2 | x2 | 1.6 | 1.5 |
| x0 | x1 | x2 | |
|---|---|---|---|
| x0 | 0.0223 | -0.039 (-0.530) | -0.150 (-0.657) |
| x1 | -0.039 (-0.530) | 0.24 | 0.17 (0.230) |
| x2 | -0.150 (-0.657) | 0.17 (0.230) | 2.32 |
[40]:
plt.errorbar(data_x, data_y, sigma_y, sigma_x, fmt="o", label="data")
x = np.linspace(data_x[0], data_x[-1], 200)
par = np.array(m.values)
plt.plot(x, f(x, par), label="fit")
plt.legend()
# check fit quality
chi2 = m.fval
ndof = len(data_y) - 3
plt.title(f"$\\chi^2 / n_\\mathrm{{dof}} = {chi2:.2f} / {ndof} = {chi2/ndof:.2f}$");
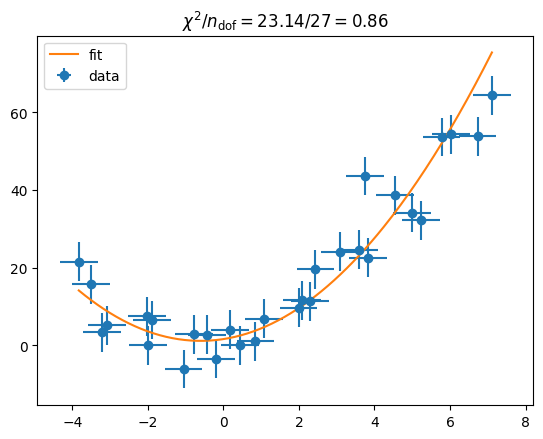
We obtained a good fit.